关系数据库的简单概念和范式理解
相关概念
讲解
首先说明 键字=码字,所以 主键=主码=主关键字,候选键=候选码=候选关键字
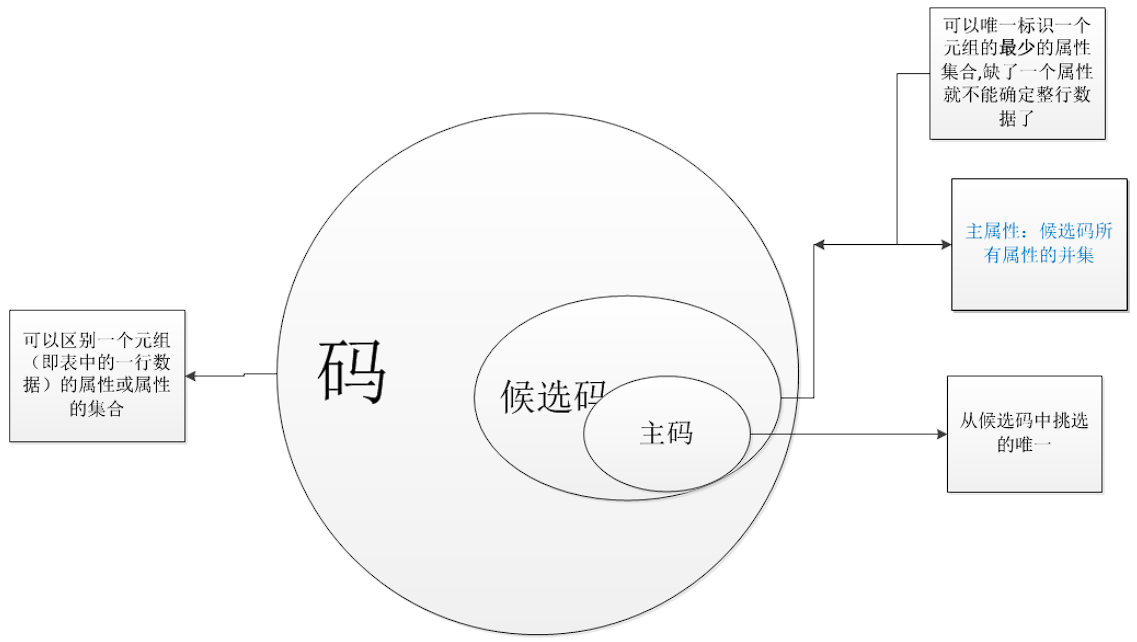
码=超键:能够唯一标识一条记录的属性或属性集。
- 标识性:一个数据表的所有记录都具有不同的超键
- 非空性:不能为空
- 有些时候也把码称作“键”
候选键=候选码:能够唯一标识一条记录的最小属性集
- 标识性:一个数据表的所有记录都具有不同的候选键
- 最小性:任一候选键的任何真子集都不能唯一标识一个记录(比如在成绩表中(学号,课程号)是一个候选键,单独的学号,课程号都不能决定一条记录)
- 非空性:不能为空
- 候选键是没有多余属性的超键
- 举例:学生ID是候选码,那么含有候选码的都是码。
- 少部分地方也有叫超级码的,但是见得不多
主键=主码:某个能够唯一标识一条记录的最小属性集(是从候选码里人为挑选的一条)
- 唯一性:一个数据表只能有一个主键
- 标识性:一个数据表的所有记录都具有不同的主键取值
- 非空性:不能为空
- 人为的选取某个候选码为主码
主属性:包含在任一候选码中的属性称主属性。简单来说,主属性是候选码所有属性的并集
非主属性:不包含在候选码中的属性称为非主属性。 非主属性是相对于主属性来定义的
外键(foreign key):子数据表中出现的父数据表的主键,称为子数据表的外键
全码:当所有的属性共同构成一个候选码时,这时该候选码为全码
代理键:当不适合用任何一个候选键作为主键时(如数据太长等),添加一个没有实际意义的键作为主键,这个键就是代理键。(如常用的序号1、2、3)
自然键:自然生活中唯一能够标识一条记录的键(如身份证)
举例
学生成绩信息表中有(学号、姓名、性别、年龄、系别、专业等)
超键/码:
由于学号能确定一个学生,因此学生表中含有学号的任意组合都为此表的超键。如:(学号)、(学号,姓名)、(学号,性别)等
若我们假设学生的姓名唯一,没有重名的现象。
学号唯一,所以是一个超键
姓名唯一,所以是一个超键
(姓名,性别)唯一,所以是一个超键
(姓名,年龄)唯一,所以是一个超键
(姓名,性别,年龄)唯一,所以是一个超键
候选键:
学号唯一,而且没有多余属性,所以是一个候选键
姓名唯一,而且没有多余属性,所以是一个候选键
(姓名,性别)唯一,但是单独姓名一个属性就能确定这个人是谁,所以性别这个属性就是多余属性,所以(姓名,性别)不是候选键
(姓名,年龄),(姓名,性别,年龄)同上,也不是候选键
主键:
主键就是候选键里面的一个,是人为规定的,例如学生表中,我们通常会让“学号”做主键,学号能唯一标识这一个元组。
外键:
外键就很简单了,假如我们还有一个教师表,每个教师都有自己的编号,假设老师编号在教师表中是主键,在学生表中它就是外键
练习


函数依赖
在一个表里面,属性X可以映射到属性Y,也就是说知道了X就能确定Y,称X为决定因素。
有一个关系模式S(Sno,Sname,Sage)
如果知道了一个学生的学号Sno,那我就能确定他的姓名Sname和年龄Sage。
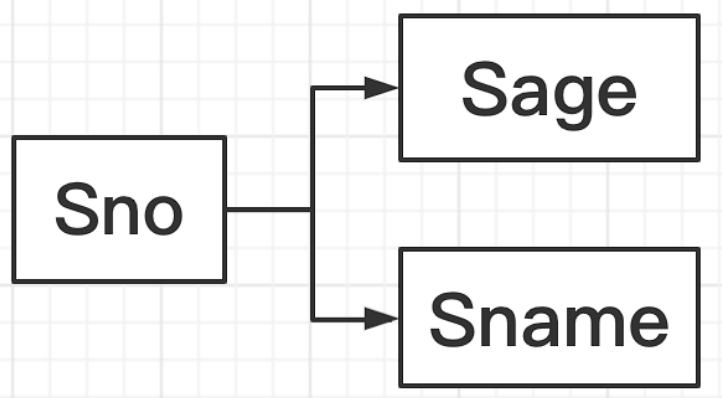
如果强制规定学生姓名不能重复。那么,知道了一个学生的姓名也是可以确定其他属性的,这也是满足函数依赖关系的。
完全函数依赖
有一个关系模式S(Sno,Sname,Cno,Grade)
如果我想知道某位学生的某一门课的成绩Grade,那我必须得同时知道他的学号Sno和课程号Cno。
但如果我只知道一部分信息,比如他的Sno或者Cno可以吗?答案是不行的!此时称Y[Grade]完全依赖于X[Sno,Cno]。

部分函数依赖
如果我想知道某位学生的姓名Sname,那我知道他的学号Sno就可以了。也就是说Y[Sname]只函数依赖于X[Sno,Cno]中的子集x[Sno],此时称Y部分函数依赖于X。

传递函数依赖
有一个关系模式S(Sno,Sdept,Mname)
如果我知道了一个学生的学号Sno,那我就能知道他所在的系Sdept。(因为理论上一个学生只属于一个系)
如果我知道了某一个系Sdept,那么我就能知道这个系的系主任的姓名Mname。(一个系只有一个正的系主任)
也就是说,我知道了一个学生的学号Sno,其实我就知道了他所在系的系主任的姓名Mname。但这个过程中,他们是不存在直接函数依赖的,我需要通过系名称Sdept作为一个桥梁去把二者联系起来的。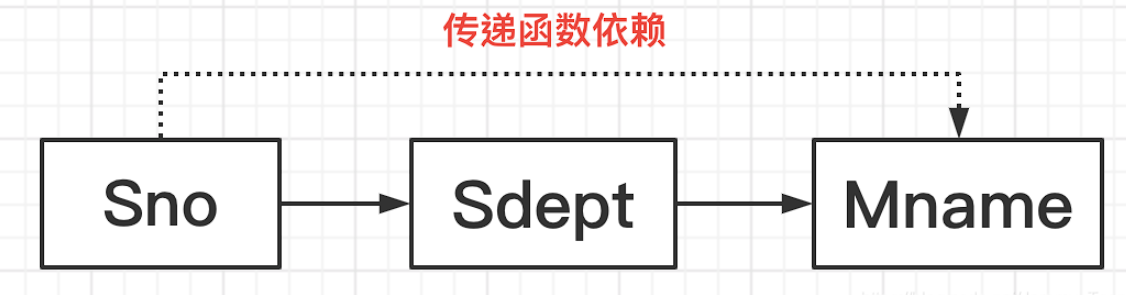
范式
关系数据库中的模式设计要满足一定的规范,引入了范式这一概念。
不管做哪种范式的设计,最终要的思想是“one fact in one place”,也就是“一事一地”。
举例
现有一关于学生的关系模式Student(学生编号 , 学生姓名, 班级编号, 院系, 课程编号 , 成绩)
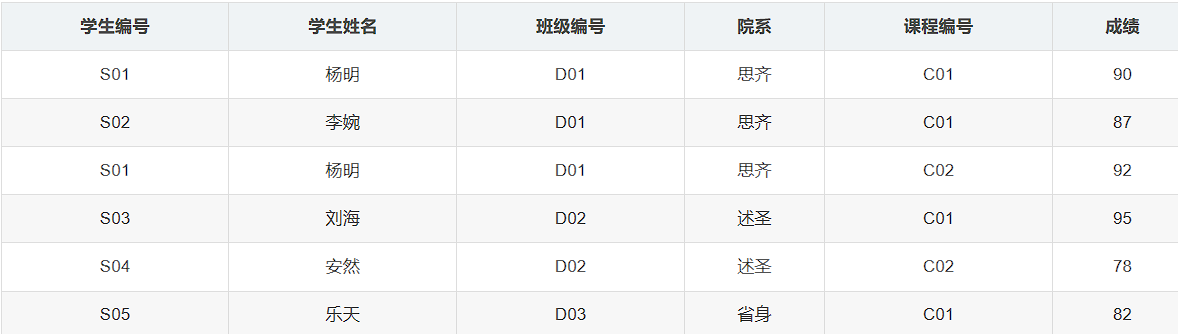
(学生编号、课程编号)作为主键,可以唯一标识每条元组
1NF
定义:关系中每一分量不可再分。即不能以集合、序列等作为属性。(也就是不能表中套表,要保证数据的原子性。)
| 学生编号 | 课程编号 |
|---|---|
| S01 | {C1,C2,C3} |
| S02 | {C1,C4} |
它就不满足1NF,因为{C1,C2,C3}和{C1,C4}是集合。
修改为符合1NF:
| 学生编号 | 课程编号 |
|---|---|
| S01 | C1 |
| S01 | C2 |
| S01 | C3 |
| S02 | C1 |
2NF
定义:在1NF基础上,消除非主属性对键的部分依赖,则称它符合2NF。
对于学生姓名、学生所属的班级编号、院系,这三个属性可以直接通过学生编号来确定,在这里课程编号#显得很多余。也就是,学生姓名、班级编号、院系对(学生编号、课程编号)部分函数依赖。把Student表进行拆分,可以消除部分依赖。
其中,学生表Student如下:
| S01 | 杨明 | D01 | 思齐 |
|---|---|---|---|
| S02 | 李婉 | D01 | 思齐 |
| S01 | 杨明 | D01 | 思齐 |
| S03 | 刘海 | D02 | 述圣 |
| S04 | 安然 | D02 | 述圣 |
| S05 | 乐天 | D03 | 省身 |
学生-课程表如下:
| 学生编号 | 课程编号 | 成绩 |
|---|---|---|
| S01 | C01 | 90 |
| S02 | C01 | 87 |
| S01 | C02 | 92 |
| S03 | C01 | 95 |
| S04 | C02 | 78 |
| S05 | C01 | 82 |
3NF
定义:在2NF基础上,消除非主属性对键的传递依赖,则称它符合3NF。
根据上面对传递依赖的分析,对于Student表,学生编号可以唯一确定他所在的院系,但是注意到这中间存在传递过程,即学生编号唯一确定该学生所对应的班级编号,班级编号对应唯一的院系。我们称,院系对学生编号传递函数依赖。
把Student表继续进行拆分,可以消除传递依赖。
其中,学生表Student如下:
| 学生编号 | 学生姓名 | 班级编号 |
|---|---|---|
| S01 | 杨明 | D01 |
| S02 | 李婉 | D01 |
| S01 | 杨明 | D01 |
| S03 | 刘海 | D02 |
| S04 | 安然 | D02 |
| S05 | 乐天 | D03 |
班级-院系表如下:
| 班级编号 | 院系 |
|---|---|
| D01 | 思齐 |
| D02 | 述圣 |
| D03 | 省身 |
BCNF
每个非主属性必须直接(或完全)依赖于候选键的所有属性,而不是候选键的一部分。
参考
数据库函数依赖——完全函数依赖、部分函数依赖、传递函数依赖【通俗易懂,博主会讲人话】_完全函数依赖和部分函数依赖怎么理解-CSDN博客